[论文地址]
Outline
本文针对一个更具挑战的任务:同时进行姿态检测和跟踪。
- 单人姿态估计(ResNet backbone + deconvolutional layers)
- 贪婪匹配方法用于姿态跟踪(Detect and Track)
- use optical flow based pose propagation and similarity measurement
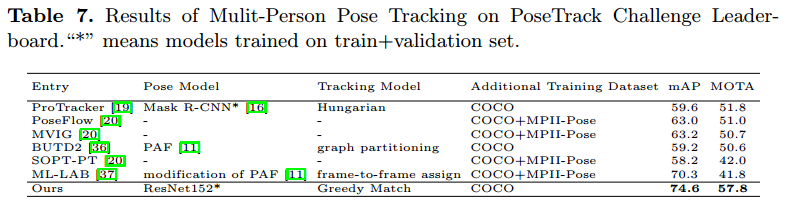
Result: 74.6 mAP, 57.8 MOTA
网络结构
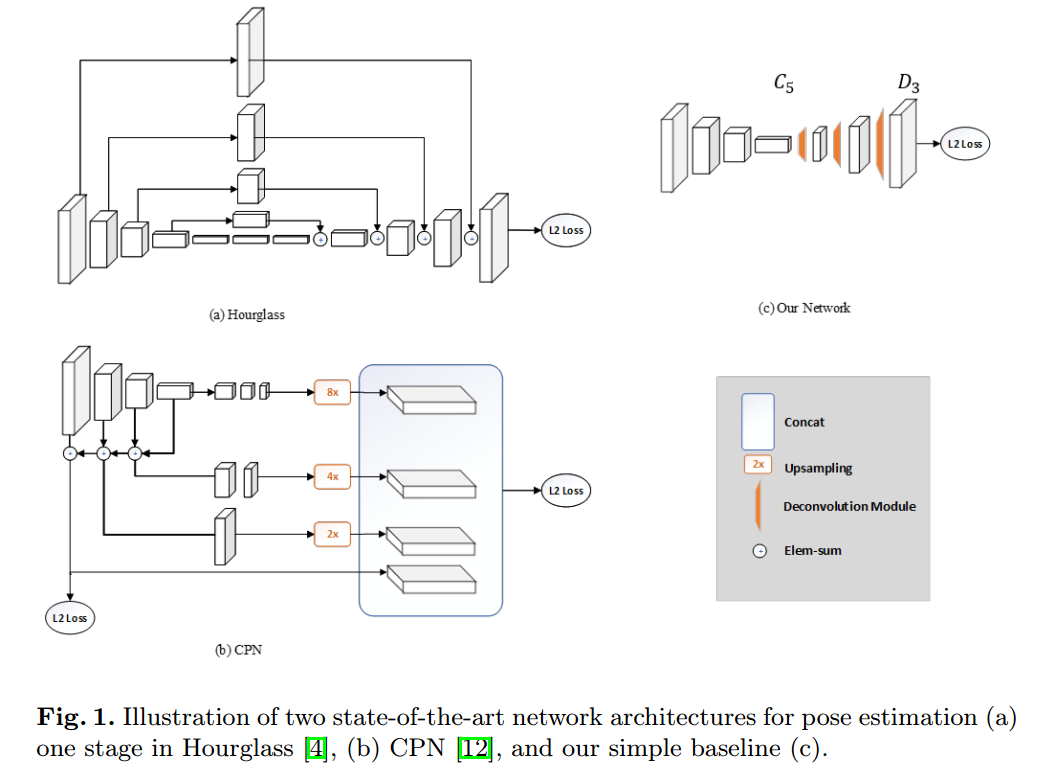
与 Hourglass 网络和 CPN 对比:
Hourglass & CPN 采用了上采样来增大模型分辨率,并将卷积参数用于其他的模块;而本文方法将上采样和卷积参数以转置卷积(deconvolutional layer)的方式结合,不使用跳跃连接(skip layer connections)。
算法框架
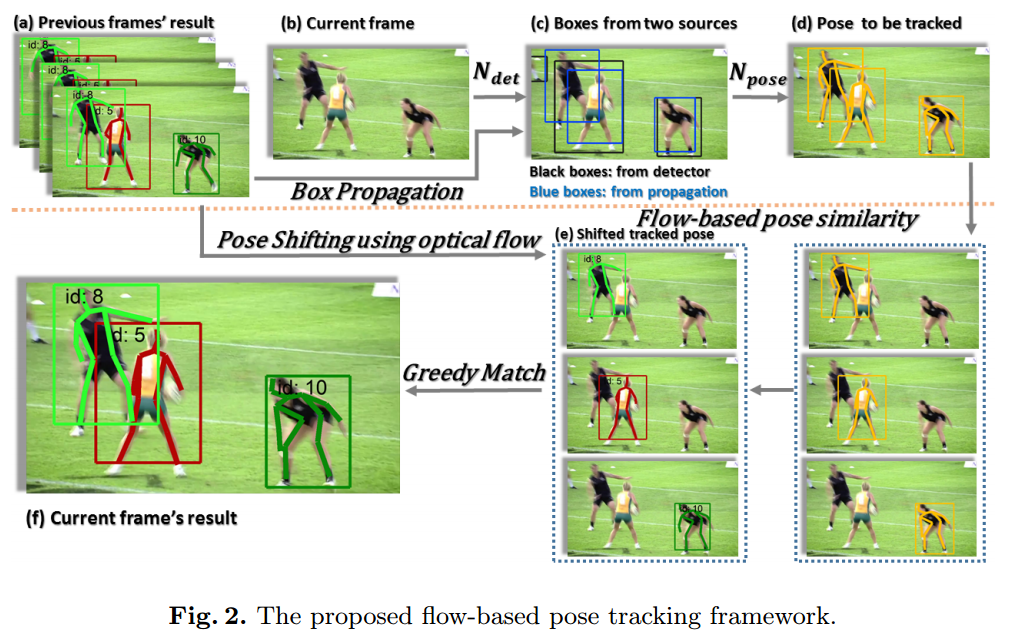
单帧姿态估计
通过在帧间指派 id 来跟踪人体姿态
当处理第k帧 $I_k$ 时,我们已经得到了第k-1帧 $I_{k-1}$ 中人实例的集合 $P_{k-1}={p_i}, p_i=(\mathrm{joints}_i,\mathrm{id}_i)$,其中 id 表示轨迹;以及实例集合 $P_k={p_j}, p_j=(\mathrm{joints}_j, \mathrm{id}_j=\mathrm{None})$.
如果 $p_j$ 链接到一个 $p_i$,那么 $\mathrm{id}_i$ 分配给 $\mathrm{id}_j$,否则一个新的 id 被指派给 $p_j$,表示一个新的轨迹。
采用光流的 box propagation
直接采用基于图像的检测器(e.g. R-FCN)存在的问题:由于视频帧的运动模糊和遮挡,可能会漏检和误检。通常引入时间信息来生成更鲁棒的检测结果。
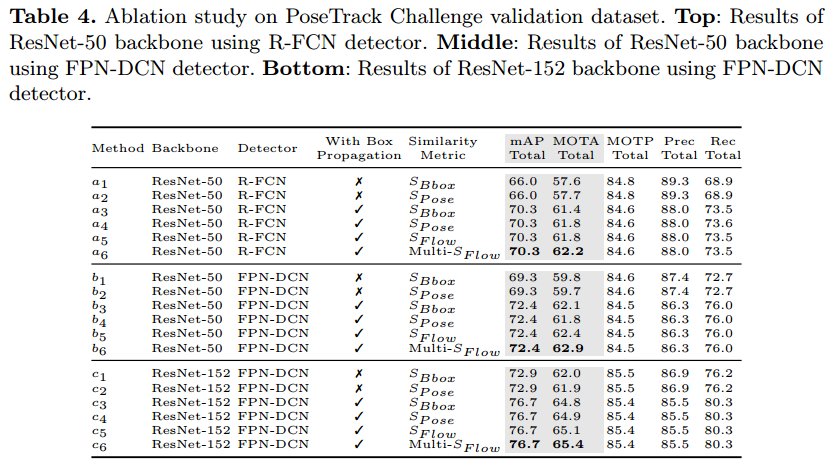
本文提出通过光流表示的时间信息来从相邻帧获得boxes。给定帧 $I_{k-1}$ 中人的实例 $p_i=(\mathrm{joints}_i, \mathrm{id}_i)$ 以及帧 $I_{k-1}$ 和帧 $I_k$ 间的光流,我们可以利用光流位移 $p_i$ 的关节坐标来估计帧 $I_k$ 中对应的 $\hat{p_j}=(\hat{\mathrm{joints}_j},\mathrm{id}_j)$。然后本文通过扩大 $\hat{\mathrm{joints}_j}$ 的 min 和 max 范围(实验中为15%)来计算传播得到的边界框。
基于流的姿态相似性
相邻帧采用边界框 IoU 作为相似性度量($S_{Bbox}$)来联系实例在下述场景中会存在问题:当一个实例移动得很快,相邻帧的边界框没有重叠,且其处于一个密集的场景中。一个更精细的度量是姿态相似性($S_{Pose}$),它通过目标关键点相似性(OKS)来计算两个实例间的人体关节距离。姿态相似性在同一个人在不同的帧间姿态变化时可能存在问题。本文提出了一个基于流的姿态相似性度量。
利用 $I_k$ 和 $I_l$ 帧间的光流位移人体关节坐标来从 $p_i$ 得到 $\hat{p_i}$。可利用 $I_l$ 中的 $p_j$ 和 $\hat{p_i}$ 的相似性来代理 $p_j$ 和 $p_i$ 是同一个人的相似性。
给定帧 $I_k$ 中的实例集合 $P_k={p_i}$ 以及帧 $I_l$ 中的实例集合 $P_l={p_j}$ ,基于流的姿态相似性度量如下表示:
$$
S_{Flow}(P_k,P_l)=\mathrm{OKS}(\hat{P_k},P_l)
$$
由于不同的人和物体之间会产生遮挡,人可能在视频中消失又重新出现。仅考虑连续的两帧是不够的,因此我们的姿态相似性度量考虑了多帧($\mathrm{Multi-}S_{flow}$),意味着 $\hat{P_k}$ 可能从多帧之前位移得到。
基于流的姿态跟踪算法

- 姿态估计。对于当前处理帧,检测框由行人检测器和之前帧利用光流得到的框组成,并进行非极大抑制(NMS)操作。然后将剪裁和缩放的图片送入姿态估计网络进行姿态估计。
- 跟踪。将跟踪的实例储存在一个记忆池 $P_{pool}$ 中,它在视频的第一帧初始化,可以用来捕获多帧的联系。对于第 i 帧 $I_i$,我们计算未跟踪的 $P_i$(id 为 None)和 $P_{pool}$ 基于流的姿态相似性矩阵 $Sim$。然后采用贪婪匹配和 $Sim$ 将 id 分配给 $P_i$。最后将新的实例结果 $P_i$ 加入 $P_{pool}$。$P_{pool}$ 由一个长度固定的两端队列(Deque)实现,队列长度 $pool_{len}$ 表示进行匹配时考虑的前帧数。
实验结果
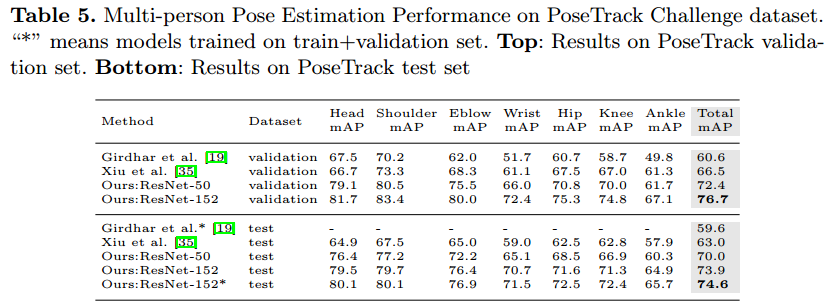
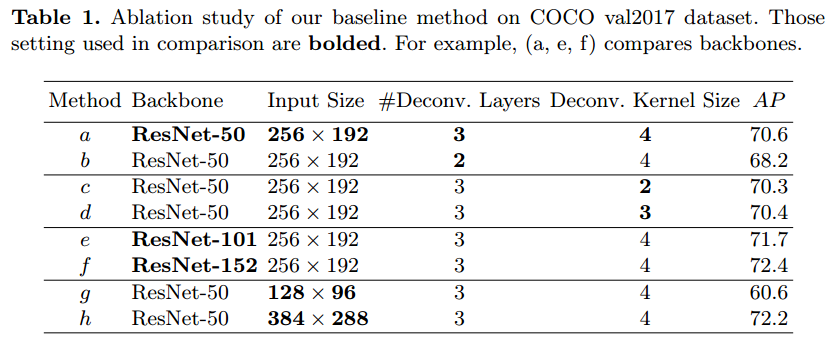
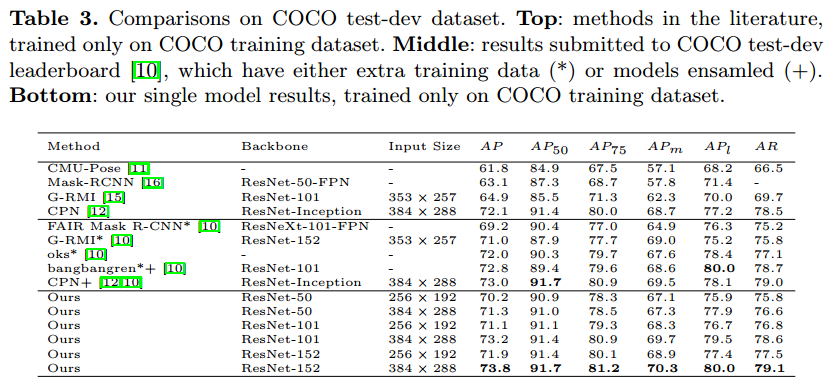
COCO 姿态估计

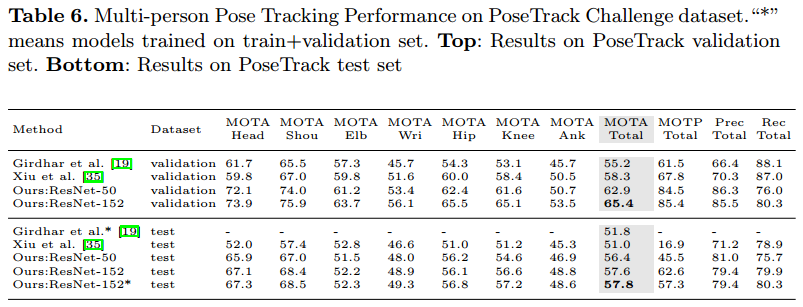
PoseTrack 姿态估计和跟踪
- Task 1:单帧姿态估计 mAP
- Task 2:多帧姿态估计 mAP,可使用帧间的时间信息
- Task 3:姿态跟踪 MOTA