Associative Embedding: End-to-End Learning for Joint Detection and Grouping
设计思想
Multi-Person Pose Estimation 的方法主要分为两类:
- Top-Down方法:
- 首先在图像上进行行人检测,得到边界框;再在每个人体边界框内进行 Single-Person Pose Estimation
- 优点:Single-Person Pose Estimation 的后处理简单,仅需选取 heatmap 上响应最大的位置作为关键点坐标;在行人检测阶段实现了多尺度的检测,姿态估计仅需运行在单一尺度上。
- 缺点:需要对检测到的每个人体边界框运行一次 Single-Person Pose Estimation,运行速度受图像中人数影响较大;当多个人相互遮挡比较严重时,边界框内可能包含其他人的身体部位,影响关键点检测的结果(e.g. 对于某个特定部位,Single-Person Pose Estimation 算法至多只会检测出一个关键点,而边界框内包含多个关键点,算法不一定能鉴别出当前人的关键点)。
- Bottom-Up方法:
- 对整幅图像进行关键点检测,再将检测到的关键点组合成人。
- 优点:关键点检测在图像上仅运行一次,速度较快,且受图像中人数影响较小。
- 缺点:由于关键点数量不确定,非极大值抑制、将关键点组合成人的处理比较复杂;图上的人可能具有不同的尺度,需要增加姿态估计模型对多尺度的处理能力。
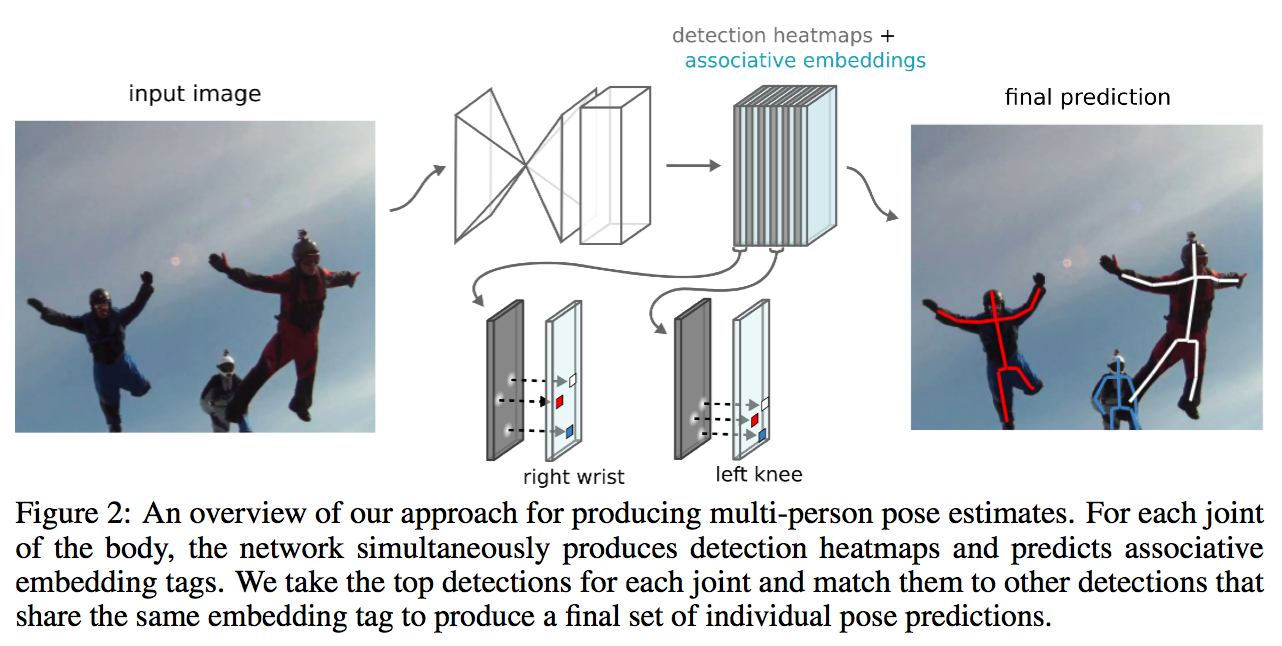
《Associative Embedding: End-to-End Learning for Joint Detection and Grouping》这篇论文更接近于 bottom-up 方法,不同的是没有 detection 和 grouping 步骤的区分,相比于过去的 bottom-up 方法,后处理较为简单。论文训练模型同时生成 keypoints detection 所需的 heatmaps 和 grouping 所需的 tags。“Tags” 用于判断哪些关键点属于同一个人。主要的想法是同时做 pose estimation 和 instance segmentation(但此处的segmentation比较粗糙,仅用于区分不同的人)。

模型结构
采用 Stacked Hourglass 结构,并改进如下:
- 增加特征通道数,为分辨率低的特征图设置更多的通道数;
- 用 3x3 卷积代替原来的残差模块;
- 同时预测 keypoints heatmap 和 tag heatmap(indicating which person a detected joint belongs to). 每个 keypoint heatmap 都有其对应的 tag heatmap(s).
不足与补充
对于图像中尺度较小的人,在池化后分辨率很低,使得识别效果较差。论文模型未加入多尺度处理的设计,而是在测试时采用多尺度的图像输入。